SOAR: Using Tesseract to parse SMS images

Intro
In a recent security-related engagement, we were tasked with helping a client who was facing challenges in automating SMS phishing incidents reported via email from both their staff and customers. Although the client had an established phishing automation process and an existing SOAR platform in place, they needed a solution to automate the recognition of characters in images containing SMS phishing messages.
To address the challenge, we proposed using Tesseract, a neural network-based OCR engine specifically designed for line recognition. Tesseract can accurately recognize characters in images and convert them into plain-text format.
To integrate Tesseract with the client’s existing SOAR platform, we utilized Python and FASTAPI to develop a custom solution. This solution allowed the client to submit an image or a base64-encoded image string, which the program would then process and return the full message or lines of text in JSON format. Additionally, the program would extract any URLs contained within the message using regular expressions and present them in a separate structure.
By leveraging Tesseract, Python, and FASTAPI, we were able to provide the client with a quick and effective solution that streamlined their SMS phishing incident response process.
Installation
Provision an AWS / other cloud provider image
We are not going to cover and skip the provisioning of AWS EC2 linux compute instances as this is well known. Or your other favourite cloud provider.
Installing Python3 on AWS Linux
Run the following commands to install python3 and verify the version:
sudo amazon-linux-extras enable python3.8
update-alternatives --install /usr/bin/python3 python3
python3 -v
Installing build environment and dependancies
sudo yum --enablerepo=epel --disablerepo=amzn-main install libwebp
sudo yum install pango-devel cairo-devel gcc clang nginx gunicorn opencv-python
Download, build, & install Leptonica
wget https://github.com/DanBloomberg/leptonica/releases/download/1.75.1/leptonica-1.75.1.tar.gz
tar -xzf leptonica-1.75.1.tar.gz
cd leptonica-1.75.1/
./configure
make
sudo make install
Download, build, & install Tesseract
The current available packaged version of tesseract, is not that great, so we need to manually build and install the latest version and install the most recent training data:
cd ~
git clone --depth 1 https://github.com/tesseract-ocr/tesseract.git tesseract-ocr
cd tesseract-ocr
./autogen.sh
./configure
make
sudo make install
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
sudo pip3 install setuptools
sudo pip3 install pytesseract
sudo pip3 install tesserocr
sudo ln -s /usr/local/bin/tesseract /bin/tesseract
And download and install the training data:
wget https://github.com/tesseract-ocr/tessdata/blob/main/eng.traineddata?raw=true
mv eng.traineddata\?raw\=true eng.traineddata
mv /usr/share/tesseract/tessdata/eng.traineddata /usr/share/tesseract/tessdata/eng.traineddata.old; cp eng.traineddata /usr/share/tesseract/tessdata/
Finally we confirm our tesseract version
export TESSDATA_PREFIX=/usr/share/tesseract/tessdata
/bin/tesseract --version
tesseract 5.3.0
leptonica-1.75.1
libjpeg 6b (libjpeg-turbo 2.0.90) : libpng 1.5.13 : libtiff 4.0.3 : zlib 1.2.7 : libwebp 0.3.0
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found OpenMP 201511
Setup our web engine
sudo nano /etc/nginx/sites-enabled/conf.d/myapp.conf
File contents:
server{
listen 80;
server_name <public ip here>;
location / {
proxy_pass http://127.0.0.1:8000;
}
}
Setup our Python Code and API frontend
mkdir PythonDir
cd PythonDir
nano pythoncode.py
Our code:
#!/usr/bin/env python3
import numpy as np
import sys, os
from fastapi import FastAPI, UploadFile, File,Form
from starlette.requests import Request
import io
import cv2
import re
import base64
import pytesseract
from pydantic import BaseModel
def read_img(img):
text = pytesseract.image_to_string(img)
return(text)
def FindURL(string):
# findall() has been used with valid conditions for urls in stringdef prediction(request: Request, file: bytes = File(...)):
regex = r"(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:'\".,<>?«»“”‘’]))"
url = re.findall(regex,string)
return [x[0] for x in url]
app = FastAPI()
class ImageType(BaseModel):
url: str
@app.post("/image/")
def prediction(request: Request, file: bytes = File(...)):
if request.method == "POST":
image_stream = io.BytesIO(file)
image_stream.seek(0)
file_bytes = np.asarray(bytearray(image_stream.read()), dtype=np.uint8)
frame = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)
label = read_img(frame)
text_oneline = label.replace('\n', '')
urls = FindURL(text_oneline)
e_urls= []
for url in urls:
e_urls.append(url)
return {'label': text_oneline, 'urls':e_urls}
return "No post request found"
@app.post("/base64/")
def prediction(request: Request, file: str = Form(...)):
if request.method == "POST":
try:
image_as_bytes=str.encode(file)
image_rec=base64.b64decode(image_as_bytes)
image_stream = io.BytesIO(image_rec)
image_stream.seek(0)
file_bytes = np.asarray(bytearray(image_stream.read()), dtype=np.uint8)
frame = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)
label = read_img(frame)
text_oneline = label.replace('\n', '')
urls = FindURL(text_oneline)
e_urls= []
for url in urls:
e_urls.append(url)
return {'label': text_oneline, 'urls':e_urls}
except:
return {'Error':'Failed to parse image'}
return "No post request found"
Finally, we run the pythoncode via:
gunicorn -w 1 -k uvicorn.workers.UvicornWorker pythoncode:app &
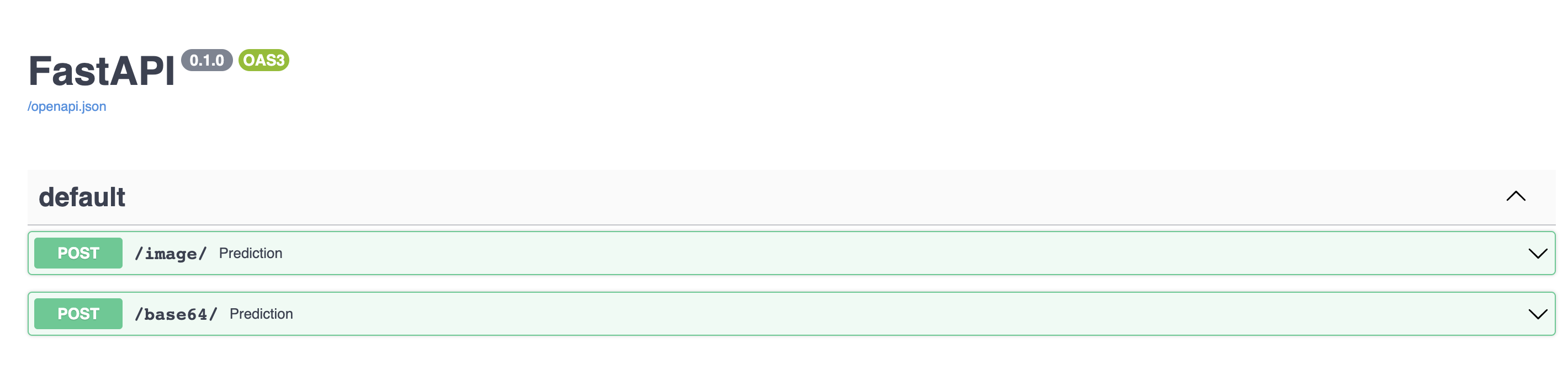
The API interface
The interface over HTTP looks like:
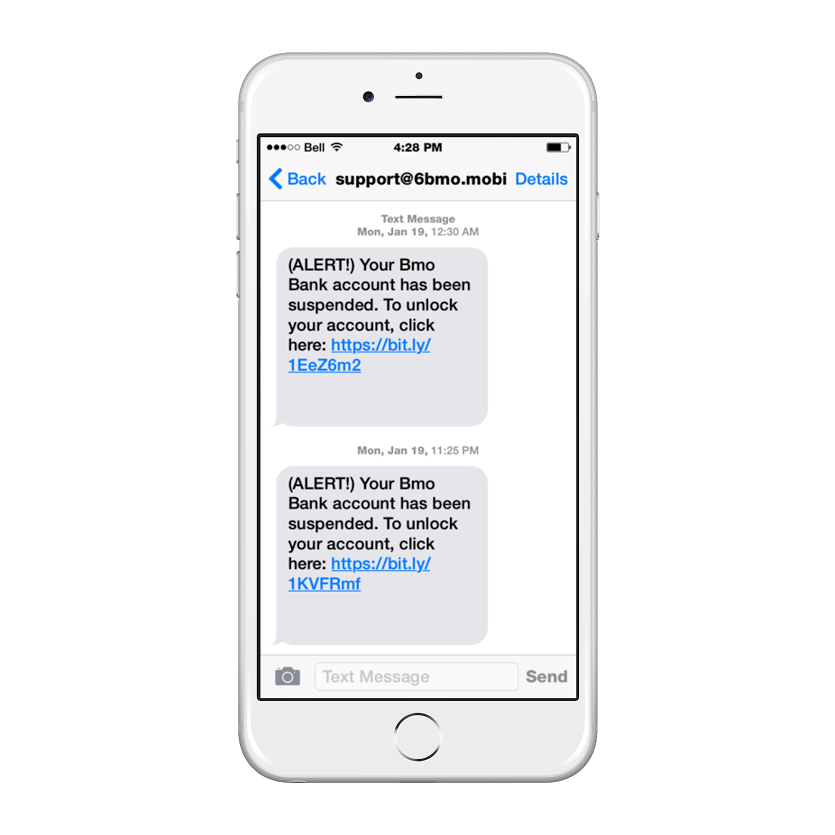
We will use the following test SMiSh screenshot as an example of the picture to text capabilities of tesseract:
The API returns the text, and we have also extracted one of the URL’s
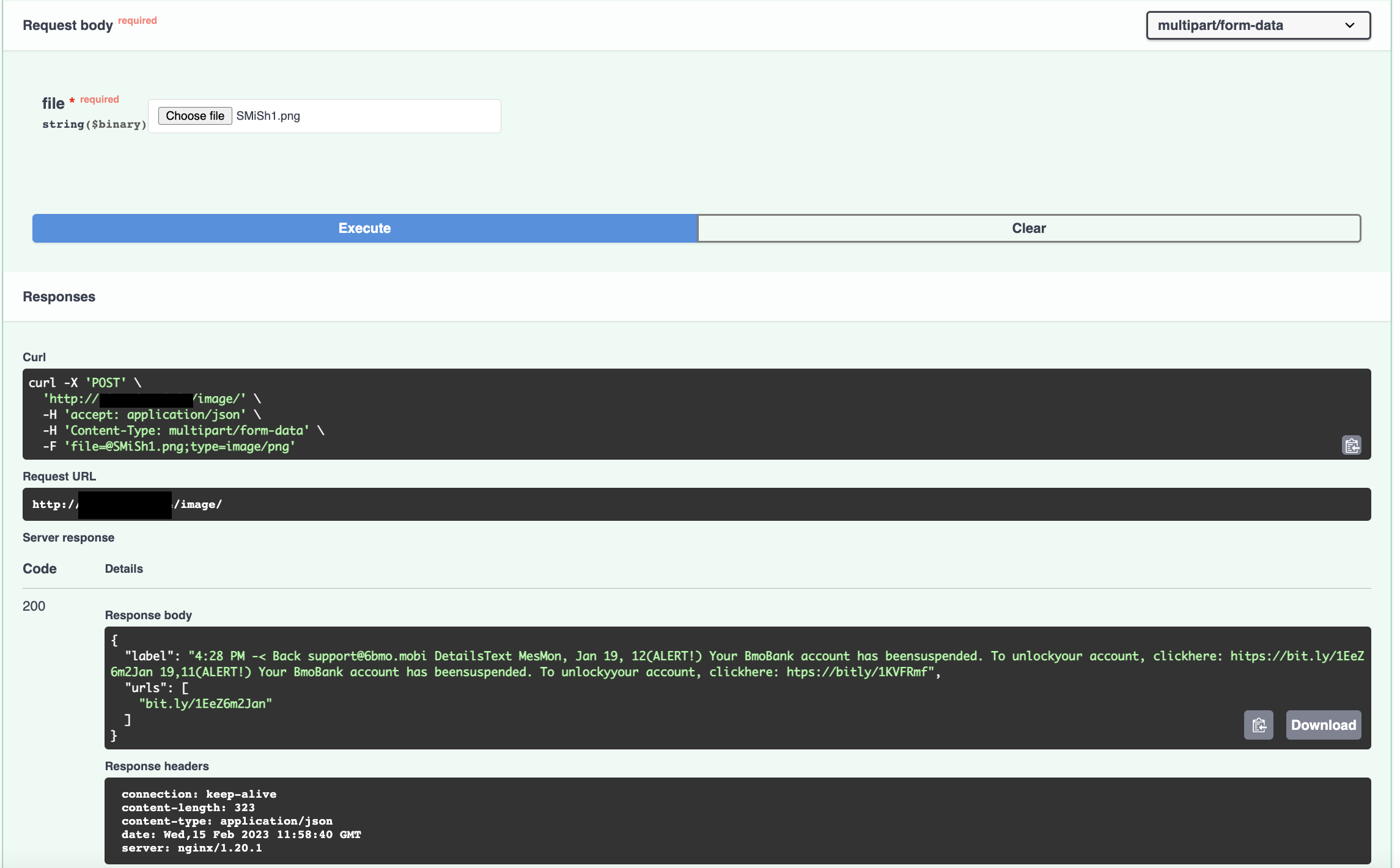
This text output can easily be processed by any automation or SOAR platform.
Running the program on the commandline with a base64 encoded image, equally works as expected:


Conclusion
In conclusion, the successful implementation of Tesseract OCR engine, Python, and FASTAPI for automating the parsing of SMS phishing messages has demonstrated the potential for organizations to enhance their security operations. By following the steps outlined in this blog post, readers can replicate this project and deploy their own customized solution to automatically detect and extract SMS phishing messages.
This solution provides a faster, more efficient, and more accurate approach to detecting and responding to SMS phishing incidents, which are becoming increasingly common in today’s threat landscape. As organisations face mounting pressure to safeguard their sensitive data and protect their users from harm, solutions like these can play a critical role in improving their overall security posture.
Share on: