AWS Athena and Cloudfront Logs
The Problem
The only problem with Athena is that it does not understand the default output format of Cloudfront logs. Things would be so much simpler if it could intelligently parse the Cloudfront logs (but maybe this is a future idea for AWS?). In the meantime me need to roll our own solution for moving our Cloudfront logs into a structure that Athena can easily digest.
For those whom not familiar with Athena Table Partition; Partition is simply indicating where the data is stored (e.g. a folder structure), with some flag parameters that can be used for identifying a given partition. The reason why you need this, is to let Athena only scan the data that you need it to scan; This will save you from reading in potenital GBs of data, and is a cost saving exercise.
However, when you write any queries, Athena will attempt to ‘‘read all’’ the data! But if there is partition such as year / month / day / hour and you have additionally already registered those partitions, such as
year=2019/month=01/day=01/hour=00 -- s3://logs/2019/01/01/00/
Then you can simply use a where clause and with the partition indices to restrict Athena, to only read the data your interested in:
SELECT uri, count(1)
FROM cloudfront_logs
WHERE status = 500
AND (year || month || day || hour) > ‘2019010100’
And Athena will read conditions for partition from where first, and will only access the data in given partitions only. As a result, This will only cost you for sum of size of accessed partitions.
The Solution in 2 Parts
- Use lambda to copy the Cloudfront logs into a structure Athena can process
- Build Athena tables as partitions to save on running costs
Creating the Lambda
Create a lambda function:
- Name = Cloudfront-Process-Logs
- Type = Python 2.7
Create a Trigger
- Type = S3
- Object = All Objects Created
- Prefix = /logs (assuming Cloudfront prefixes /logs to your log files)

Once successful your trigger should look simiklar to ours above.
Source
Python 2.7 lambda, originally sourced from Bray Almini, but modified for our needs:
# https://github.com/Brayyy/Lambda-CloudFront-Log-Restructure
# Initial release 2017.05.17 - Bray Almini
import boto3
def lambda_handler(event, context):
s3 = boto3.client('s3')
print("Im trying to work with your logs")
# Iterate over all records in the list provided
for record in event['Records']:
# Get the S3 bucket
bucket = record['s3']['bucket']['name']
# Get the source S3 object key
key = record['s3']['object']['key']
# Get the CloudFront distribution id from the source S3 object
#distro = key.split('/')[1]
#print(distro)
# Get just the filename of the source S3 object, increase to 2 if use distro
filename = key.split('/')[1]
#print("f: %s" % filename)
# Get the CloudFront distribution id from the source S3 object
distro = filename.split('.')[0].split('/')[0]
#print(distro)
# Get the yyyy-mm-dd-hh from the source S3 object
dateAndHour = filename.split('.')[1].split('/')[0]
#print(dateAndHour)
year, month, day, hour = dateAndHour.split('-')
# Create destination path
dest = 'structured/{}/{}/{}/{}/{}/{}'.format(
distro, year, month, day, hour, filename
)
# Display source/destination in Lambda output log
print("- src: s3://%s/%s" % (bucket, key))
print("- dst: s3://%s/%s" % (bucket, dest))
# Perform copy of the S3 object
s3.copy_object(Bucket=bucket, Key=dest, CopySource=bucket + '/' + key)
# Delete the source S3 object
# Disable this line if a copy is sufficient
s3.delete_object(Bucket=bucket, Key=key)
Now everytime Cloudfront drops a log file in your log-bucket, Lambda should trigger and place a copy in a folder structure Athena can digest!
Test Data
The hardest part of getting the lambda to work was debugging, print statements just were not enough!
We extracted this sample record from our Cloudtrail, hopefully it can help you debug and adjust the lambda to your needs?
This was my test record to debug the lambda:
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "eu-west-2",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "AIDAJDPLRKLG7UEXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "C3D13FE58DE4C810",
"x-amz-id-2": "FMyUVURIY8/IgAtTv8xRjskZQpcIZ9KG4V5Wp6S7S/JRWeUWerMUE5JgHvANOjpD"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "sourcebucket",
"ownerIdentity": {
"principalId": "A3NL1KOZZKExample"
},
"arn": "arn:aws:s3:::sourcebucket"
},
"object": {
"key": "logs/xxxxxx.2019-01-07-21.a7047d29.gz",
"size": 1024,
"eTag": "d41d8cd98f00b204e9800998ecf8427e",
"versionId": "096fKKXTRTtl3on89fVO.nfljtsv6qko"
}
}
}
]
}
Populating Athena
Create db
Create a new database
create database cloudfront
Creating a Table
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
`date` DATE,
time STRING,
location STRING,
bytes BIGINT,
requestip STRING,
method STRING,
host STRING,
uri STRING,
status INT,
referrer STRING,
useragent STRING,
querystring STRING,
cookie STRING,
resulttype STRING,
requestid STRING,
hostheader STRING,
requestprotocol STRING,
requestbytes BIGINT,
timetaken FLOAT,
xforwardedfor STRING,
sslprotocol STRING,
sslcipher STRING,
responseresulttype STRING,
httpversion STRING,
filestatus STRING,
encryptedfields INT
)
PARTITIONED BY(year string, month string, day string, hour string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION 's3://my-cloudfront-logs/structured/xxx/2019/01/08/';
Adding data to a partition
By partitioning our data we keep your Athena running costs down!
ALTER TABLE cloudfront_logs ADD
PARTITION (year='2019',month='01',day='08',hour='11') LOCATION 's3://my-cloudfront-logs/structured/xxx/2019/01/08/11'
Sample Queries
Top Ten URIs
SELECT uri, status,count(*) as ct
FROM cloudfront_logs
WHERE year='2019'
AND month= '01'
AND day='08'
AND status = 200
group by uri, status
order by ct desc
limit 10
Example query:
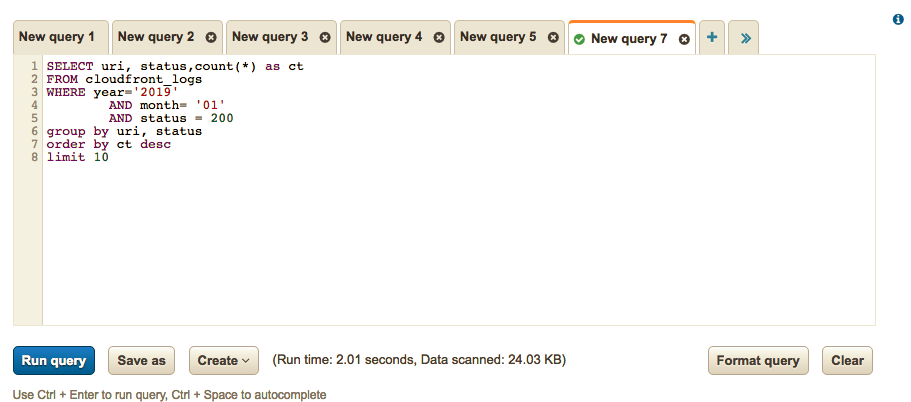
The important thing to note in this screenshot is that we’ve only process 24.03KB; thus reducing the costs on our query by limiting it to the current month.
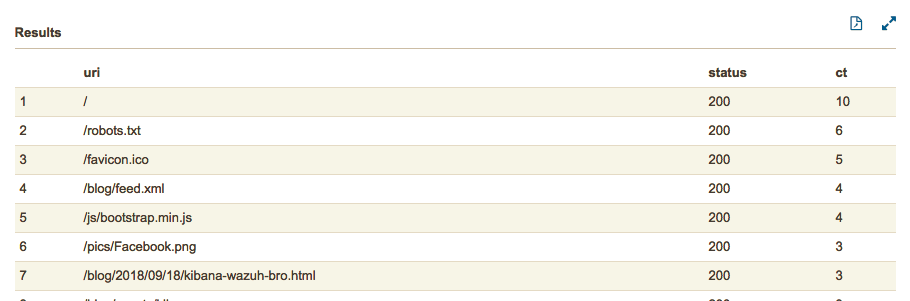
Example results:
Conclusion
We have demonstrated how you to, can utilise the power of AWS Athena to process you Cloudfront web logs for statistics or simply your curiosity. Now you can dynamically query all the things in your Cloudfront web logs.
Also with a few tweaks, the same code will work for your AWS ALBs (Application Load Balancers)!
References
Thanks to:
- Bray Almini - for his S3 structuring Lambda python program (that was modified for our purposes).
Share on: